网络爬虫的核心就是模拟浏览器,从服务器上请求数据,因此在进行网络爬虫的设计之前,我们需要搞清楚你所需要的数据从何而来,搞清楚数据是通过何种方式传输到浏览器上的。
目前来看,一个网站应用的架构分为3个部分:前端、后端、数据库。前端就是运行在我们浏览器上的html,css,js等前端程序,而网络爬虫就是通过模拟前端程序的运行逻辑来实现数据的获取。而我们这个获取数据的方式取决于后端程序通过什么方式发送数据,目前来看,大致存在两种方式进行数据的传输:一种是同步传输(直接把数据写在网页的html文件上发到浏览器上),另一种是异步传输(通过xhr等方式将某些数据交换格式(一般为json)发送到浏览器,并在js程序的处理后渲染到网页上)。网络爬虫的核心就在此。
明显的,同步传输比异步传输对于网络爬虫的分析来说是简单很多的,毕竟同步传输仅仅需要爬取网站的html文件并进行分析,而异步传输需要通过抓包来分析数据传输的整个运行逻辑,从而实现数据爬取。但是,数据的异步传输节省流量以及简单灵活等优点使得其被广泛应用,因此要在期末作业中爬取到心仪的数据,处理异步请求是难以避免的。
网络爬虫的一般分析思路
核心:网络抓包
按F12打开开发者工具(或者右键页面选”检查”),再打开“网络”
刷新页面,来记录网页加载时的网络活动
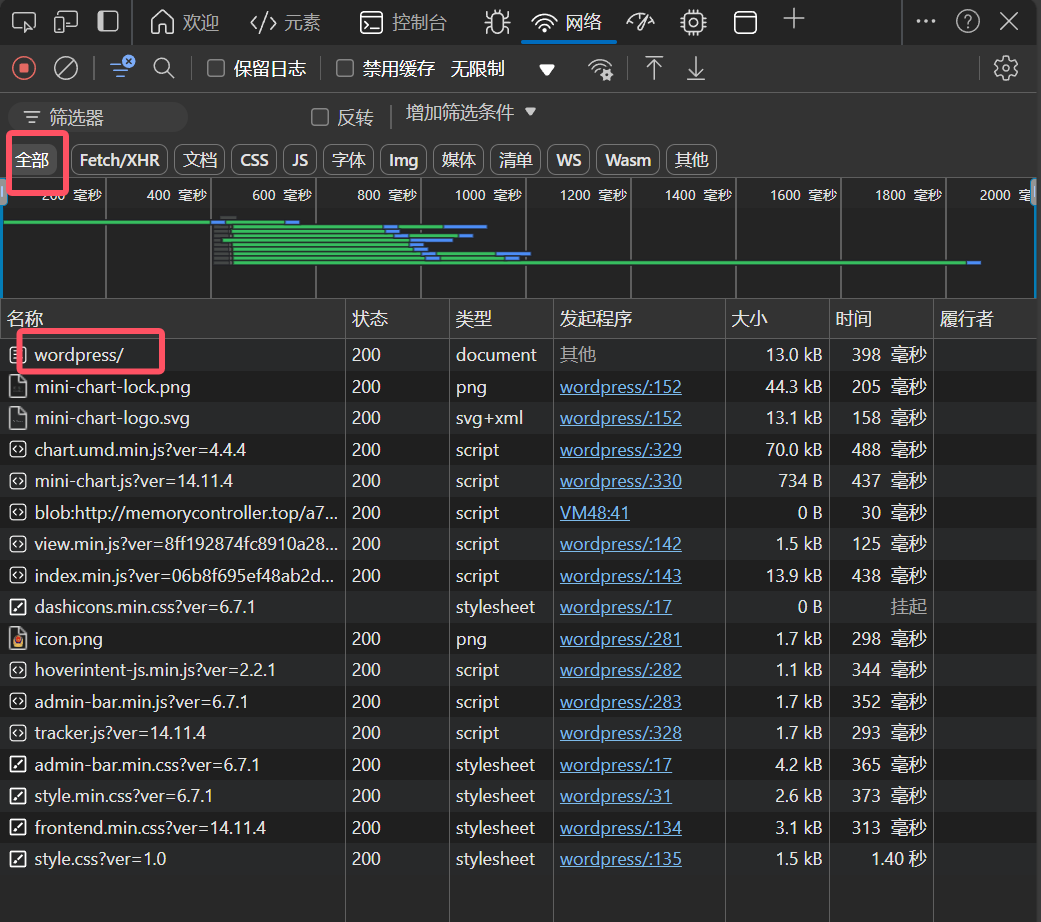
一般来说第一个就是这个网站的html文件(不会找的话就这么找)
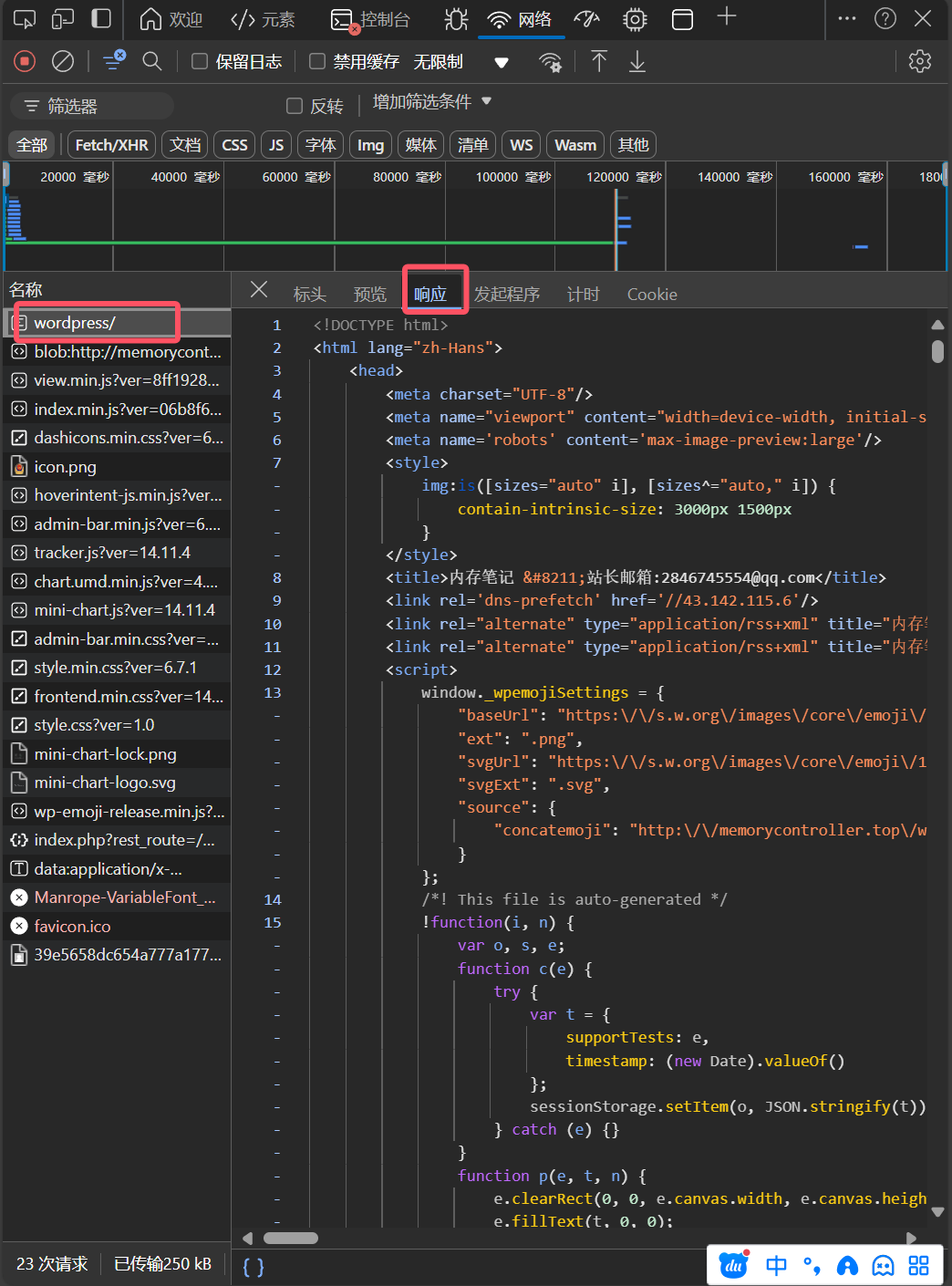
这样你就可以通过CTRL+F来查找html文件里面有没有你要的数据了。
如果有的话,那说明你需要的数据有可能是同步传输的,好处理(也有可能是运营者为节省流量设置前面多少条数据同步传输,而后面异步传输)。
如果没有的话,那就肯定是异步传输了,想省事的就可以换个网站试试了,比较执着的就可以继续研究下去。
目前我能找到的一个最好的例子就是b站的搜索功能,一个妥妥的异步请求。
(以我请求“数据结构”的搜索结果为例)
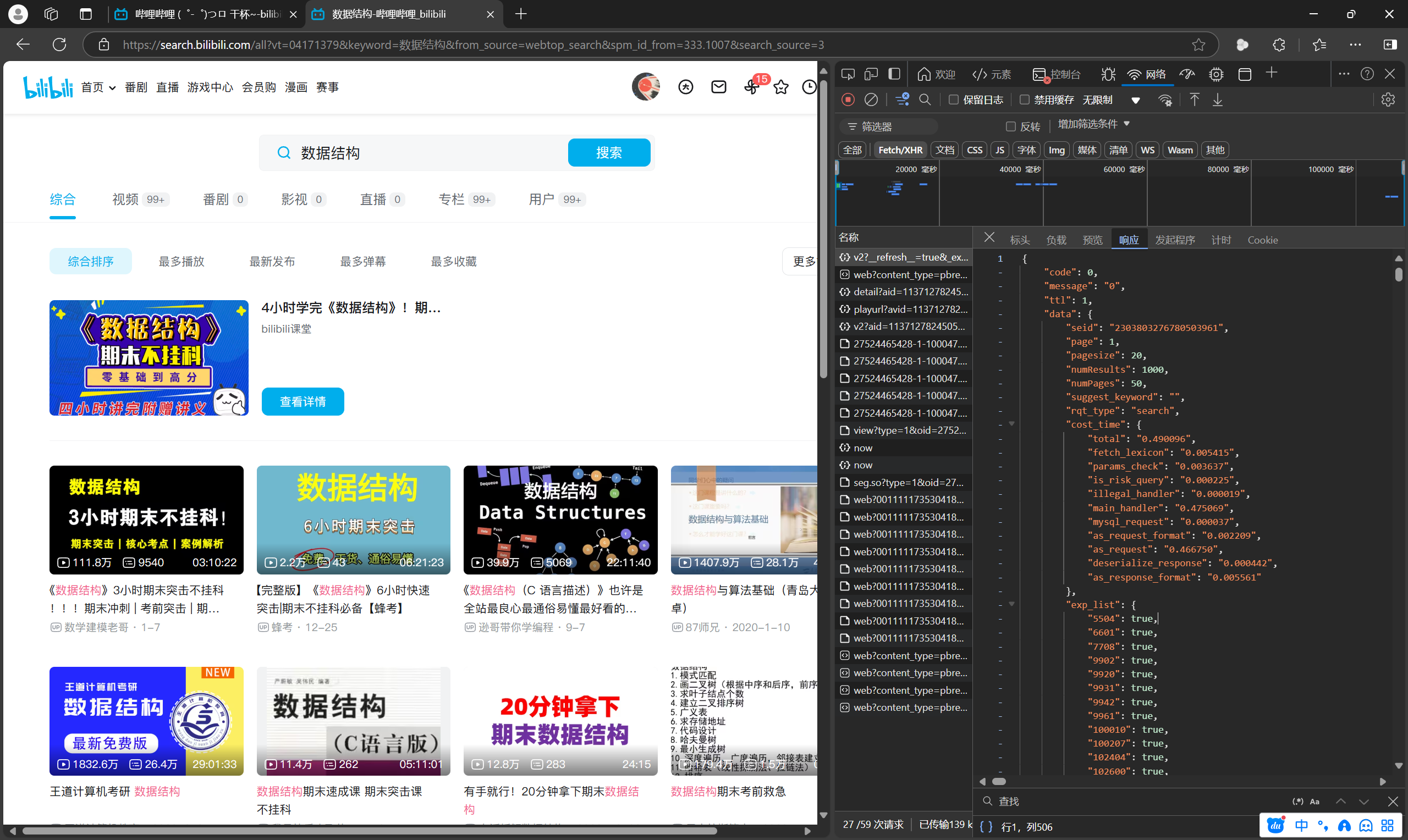
一般来说,异步请求都是用xhr方式进行的。所以我们在完成抓包之后,要在Fetch/XHR筛选器下,从上到下(时间从前到后)找相关请求的响应。这时我们就要拿出神器 Ctrl+F 大法(比如我要的是“数据结构”的结果(从页面上来看数据中包含这个字符串),所以我用“数据结构”作为关键词进行查找)
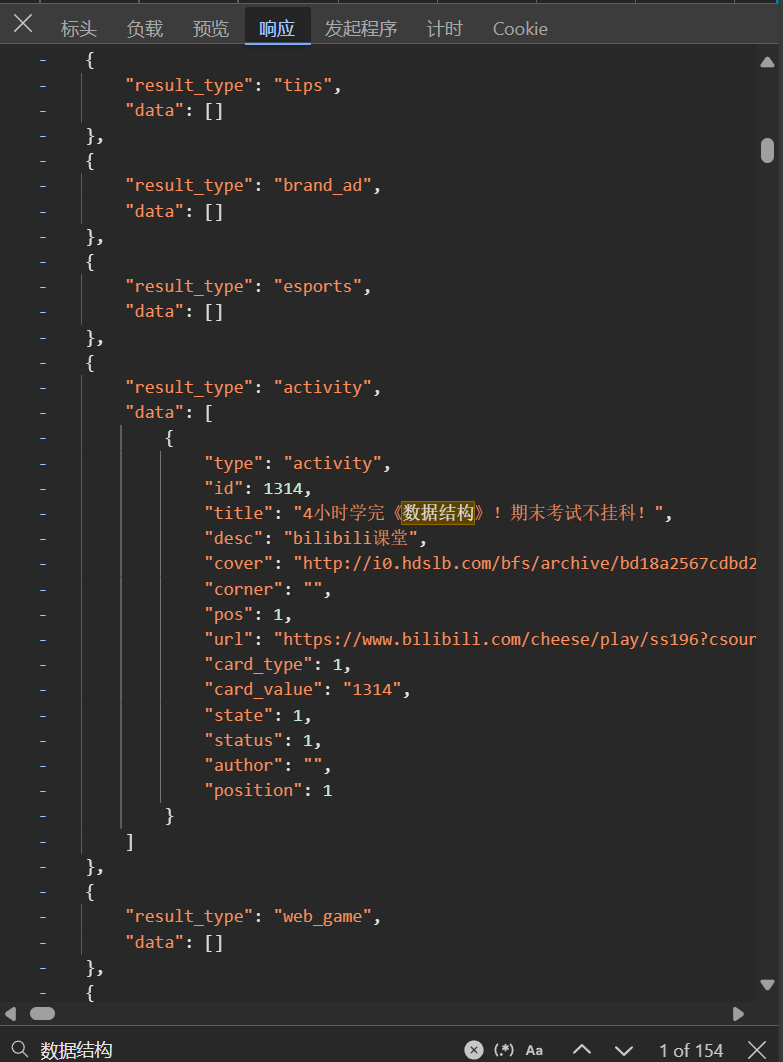
我是在xhr筛选下的第一个请求中发现我要的东西的。所以我们只要想办法把它搞下来就行了。
这时,我们就只需要关注两样东西:
一个是url(一般来说这些请求都是get方式,所以请求参数是放在url里面的,所以可以通过修改请求参数来改变你要的数据);
另一个是请求标头(主要是关注user-agent,referer,cookie,origin等,如果请求失败,则可以在请求时,按照这个顺序添加标头来尝试,实在成功不了的话可以换了,因为可能是存在会话追踪等问题,限于篇幅就不讲了)
当我们把这个异步响应的数据爬下来之后,就可以使用正则表达式来处理(就像上课讲的同步请求的处理那样),或者用json库(用json.loads函数生成一个字典和列表的嵌套结构)来采集数据。
以上就是在期末作业中我认为能用到的网络爬虫技术
文中使用的浏览器版本: Microsoft Edge版本 131.0.2903.112 (正式版本) (64 位)